文章轉(zhuǎn)載自《機(jī)器之心》
當(dāng)俄羅斯首個(gè) AI 人形機(jī)器人“艾多爾”伴著電影《洛奇》的主題曲蹣跚登場(chǎng)時(shí),所有人都以為某個(gè)高光時(shí)刻即將來臨。沒想到,“帥不過三秒”——
向觀眾揮手后,它迅速失去平衡、倒地抽搐,被工作人員匆忙拖走。

近期翻車的機(jī)器人可不止這一家。9 月,特斯拉 Optimus 因反應(yīng)遲緩被吐槽;1X 預(yù)售款的“驚艷演示”因系遠(yuǎn)程遙控,被輿論diss 到起飛。
業(yè)內(nèi)人士對(duì)此并不意外。很多演示高度依賴人工操控,大量機(jī)器人連“站穩(wěn)完成操作”都難,在工廠里“插個(gè) dongle、貼個(gè)膜”,堪比“登月”。
英特爾在與數(shù)十家具身智能團(tuán)隊(duì)溝通過程中也發(fā)現(xiàn),機(jī)器人“能跑會(huì)跳”和“能在產(chǎn)線干活”之間,還存在巨大鴻溝。
到底是什么原因阻擋它們踏入生產(chǎn)一線呢?
困在算力平臺(tái)里的具身智能
11 月 19 日,重慶·2025 英特爾技術(shù)創(chuàng)新與產(chǎn)業(yè)生態(tài)大會(huì)的圓桌現(xiàn)場(chǎng),訓(xùn)練數(shù)據(jù)、應(yīng)用、“大腦/小腦分家”的架構(gòu)問題都被擺上臺(tái)面。但有一個(gè)答案被反復(fù)提及,算力平臺(tái)正成為橫在具身智能落地面前的最大門檻之一。
目前業(yè)內(nèi)已量產(chǎn)、相對(duì)成熟的人形機(jī)器人,大多采用“大腦 + 小腦”的架構(gòu),所謂“慢系統(tǒng) + 快系統(tǒng)”——
“大腦”負(fù)責(zé)深思熟慮,承擔(dān) LLM、VLM、CNN、CLIP、SAM 等對(duì)世界建模和理解的工作;
“小腦”負(fù)責(zé)“讓身體動(dòng)起來”,對(duì)反應(yīng)速度極度敏感,包括 3D 定位導(dǎo)航、機(jī)械臂控制、步態(tài)控制等,控制頻率動(dòng)輒 500Hz~1000Hz。
過去機(jī)器人主要依賴傳統(tǒng)運(yùn)控,如今動(dòng)作生成模型、多模態(tài)感知與大模型推理層層疊加,算力需求呈幾何級(jí)增長(zhǎng)。一位現(xiàn)場(chǎng)嘉賓提到,“我們用的很多其他行業(yè)廠家的芯片,達(dá)到 100 ~ 200 個(gè) TOPS 的稀疏算力,但依然是不夠用。”而這,還只是觸及工業(yè)場(chǎng)景的冰山一角。
算力飆升之下,不少企業(yè)搞“拼湊”、搭“兩套班子”。
比如,Intel 酷睿(12/13 代移動(dòng)處理器)跑“大腦”,NVIDIA Jetson Orin 跑“小腦”,“兩套班子”還要跨芯片通信、跨系統(tǒng)協(xié)同。
結(jié)果可想而知。想想“帥不過三秒”的“艾多爾”, 視覺指令傳輸存在延遲,機(jī)器人就會(huì)摔倒。目前困擾人形擾機(jī)器人的精度、效率問題,乃至端側(cè)控制器的性能瓶頸,有一部分“歸功于此”。
算力平臺(tái)不僅是技術(shù)問題,更是落地的經(jīng)濟(jì)問題。
真正到后面小批量落地的人形機(jī)器人, ROI 肯定是我們第一個(gè)考慮的指標(biāo)。有嘉賓直言。
制造業(yè)對(duì) ROI 的考核最為嚴(yán)苛。
硬指標(biāo)上,機(jī)器人不僅要能干活,“穩(wěn)不穩(wěn)定、安不安全、貴不貴、耗不耗電”都是老板們必須算清楚的賬。
軟指標(biāo)上,為避免技術(shù)投資變成“一次性死資產(chǎn)”, 企業(yè)希望它既能迅速上線,又能隨著工廠和產(chǎn)線變化靈活擴(kuò)展或縮減。
顯然,搞“兩套班子”硬件堆疊,滿足不了這些苛刻要求(開發(fā)成本、散熱方案,功耗、價(jià)格、部署、可擴(kuò)展性等)。
現(xiàn)場(chǎng)嘉賓認(rèn)為,機(jī)器人要同時(shí)利用 CPU、GPU、NPU 多種異構(gòu)算力,如何將這些異構(gòu)算力高效整合到一塊小體積、低功耗芯片里,還要讓它們高度協(xié)同、被開發(fā)者輕松調(diào)用,是一道極大的挑戰(zhàn)。
而且,隨著具身智能加速演進(jìn),算力融合、擴(kuò)展和利用效率,正在成為限制行業(yè)落地的關(guān)鍵瓶頸。
“解藥”:以“單系統(tǒng)”達(dá)成大小腦的“融合”
需要“兩套班子”才能完成的“大腦 + 小腦”任務(wù),如今在一套“班子”里就能搞定。這正是英特爾給出的“大小腦融合”方案——
用一顆 SoC,把智能認(rèn)知與實(shí)時(shí)控制統(tǒng)一到同一個(gè)架構(gòu)中。
這顆 SoC,就是酷睿 Ultra 處理器。它在單一封裝內(nèi)集成了 CPU、英特爾銳炫? GPU 和 NPU,并讓三者協(xié)同工作,AI推理能力、高性能CPU計(jì)算與工業(yè)級(jí)實(shí)時(shí)控制,“一手”拿捏。
是不是很像重慶火鍋的九宮格?每個(gè) IP(CPU/GPU/NPU/I/O)就像格子里的一道菜,既能選“套餐”,也能隨需求自由組合,全看機(jī)器人廠商的“口味”需求。
結(jié)果,原本必須上云的大模型推理,能直接在端側(cè)運(yùn)行,響應(yīng)更快,隱私性也更高,關(guān)鍵還很經(jīng)濟(jì)。
酷睿 Ultra 在保持類似功耗的情況下實(shí)現(xiàn)了約 100 TOPS 的 AI 算力。英特爾公司副總裁兼英特爾邊緣計(jì)算事業(yè)部的總經(jīng)理Dan Rodriguez在大會(huì)Keynote上說到。用戶不需要重構(gòu)系統(tǒng),只要升級(jí) CPU,就能讓原有產(chǎn)品具備 AI 能力。
先看看內(nèi)置的GPU 。
它擁有 77 TOPS 的 AI 算力,專門負(fù)責(zé)處理最重的視覺與大模型任務(wù)。這樣的性能足以支撐 7B~13B 級(jí)別 VLM 的運(yùn)行,對(duì)于物體識(shí)別、路徑規(guī)劃、分揀等任務(wù)已經(jīng)游刃有余。
如果開發(fā)者需要更強(qiáng)的 AI 火力(更大的 LVM、VLA 等模型),可以通過 Intel Arc 獨(dú)顯進(jìn)行擴(kuò)展。
當(dāng)算力需求沖上 千 TOPS 量級(jí),例如大模型控制全身動(dòng)作、執(zhí)行多模態(tài)長(zhǎng)鏈推理,英特爾認(rèn)為應(yīng)進(jìn)一步結(jié)合外部“云腦”或邊緣大腦來完成協(xié)同推理。
這種按需擴(kuò)展的異構(gòu)算力體系,成為具身智能順利邁向復(fù)雜任務(wù)的關(guān)鍵基礎(chǔ)。

NPU 則負(fù)責(zé)輕負(fù)載常駐任務(wù),如持續(xù)監(jiān)聽語音喚醒、動(dòng)態(tài)物體檢測(cè)等長(zhǎng)期在線的 AI 功能,保證低功耗、零感延遲的體驗(yàn)。
CPU 的價(jià)值被進(jìn)一步放大。
得益于英特爾在傳統(tǒng)機(jī)器人運(yùn)控領(lǐng)域多年的積累,以及對(duì)底層指令和架構(gòu)的深度優(yōu)化,CPU 在跑傳統(tǒng)視覺算法、運(yùn)動(dòng)規(guī)劃時(shí)比過去更快、更穩(wěn)。
比如,實(shí)時(shí)抖動(dòng)小于 20 微秒,意味著機(jī)器人的平衡控制、復(fù)雜力控、手眼協(xié)調(diào)等對(duì)延遲極敏感的運(yùn)控環(huán)節(jié),現(xiàn)在都能跑在 CPU 上。
而且,CPU 內(nèi)加入了專用 AI 加速指令,使其在視覺伺服等場(chǎng)景中,能夠分擔(dān)部分原本由 GPU 執(zhí)行的 AI 推理與軌跡規(guī)劃任務(wù)。這讓算力調(diào)度更靈活、能效更優(yōu),也更符合機(jī)器人對(duì)功耗、實(shí)時(shí)性的苛刻要求。
Dan Rodriguez還提到,明年1月發(fā)布的 Panther Lake(18A 工藝)將進(jìn)一步提升性能。圖形性能最高提升 50%,同等性能下功耗降低 40%,AI 加速力提升至 180 TOPS,并支持?jǐn)U展溫度范圍與工業(yè)級(jí)實(shí)時(shí)性,這意味著具身智能的應(yīng)用邊界將被進(jìn)一步推開。
軟件棧:三管齊下,落地按下快進(jìn)
算力之外,英特爾同時(shí)把軟件棧也配齊了。
從“機(jī)器人看什么、怎么學(xué)、怎么動(dòng)”,一直到系統(tǒng)層面的調(diào)度、驅(qū)動(dòng)、實(shí)時(shí)控制,英特爾提供了全棧套件,開發(fā)者不用“零幀”起步。
對(duì)于OXMs、ODMs、OEM等硬件制造商,英特爾準(zhǔn)備的是整機(jī)級(jí)方案AI Edge Systems。操作系統(tǒng)、驅(qū)動(dòng)、SDK、實(shí)時(shí)優(yōu)化、BSP、EtherCAT 驅(qū)動(dòng),全都打包好。
比如一個(gè)已經(jīng)打了 Preempt-RT 的 BSP,廠商不用再為實(shí)時(shí)性去改內(nèi)核,把系統(tǒng)刷進(jìn)去,機(jī)器人立刻具備“工業(yè)級(jí)心跳”。
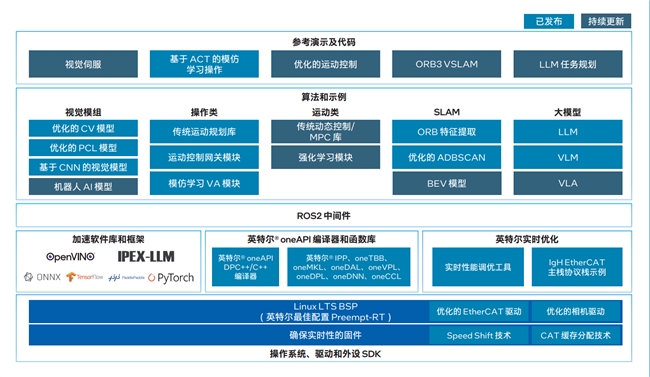
系統(tǒng)軟件廠商處在中間層,需要把芯片的每一滴算力榨到極限,為上層應(yīng)用提供最佳運(yùn)行環(huán)境。英特爾給他們準(zhǔn)備了 Open Edge Software Toolkit,里面不僅有 AI 庫和工具,更包含大量 OSV 級(jí)優(yōu)化,確保在不同平臺(tái)都能跑出穩(wěn)定性能。
這里簡(jiǎn)單提幾個(gè)英特爾構(gòu)建自家 AI 生態(tài)的關(guān)鍵抓手。一個(gè)是oneAPI——一條貫通 CPU/GPU/NPU 的“算力高速路”。
開發(fā)者寫一次代碼,系統(tǒng)自動(dòng)決定跑在哪顆單元上,CPU、GPU、NPU 甚至 FPGA,全自動(dòng)調(diào)度與優(yōu)化。
這能讓存量設(shè)施(舊機(jī)器)和增量設(shè)施(新 AI 硬件)在同一套代碼邏輯下協(xié)同工作,打破算力“孤島”。要擴(kuò)展算力?直接接上 Intel Arc 就行。
還有“黃金組合” OpenVINO + IPEX-LLM。
OpenVINO 負(fù)責(zé) AI 推理加速,把 TensorFlow、PyTorch 等模型自動(dòng)壓縮、量化、瘦身,并轉(zhuǎn)成最適合英特爾硬件執(zhí)行的格式,推理在哪塊算力單元上,也自動(dòng)決定并負(fù)載均衡。IPEX-LLM 則讓大模型在本地跑得更快。
兩者組合,可以適配不同年代、不同規(guī)格的邊緣設(shè)備,應(yīng)對(duì)工業(yè)現(xiàn)場(chǎng)設(shè)備雜、環(huán)境復(fù)雜的現(xiàn)實(shí)挑戰(zhàn)。
針對(duì)站在最上層的行業(yè)方案開發(fā)者(ISV/SI),英特爾提供了現(xiàn)成的行業(yè)模板AI Suites。抓取、導(dǎo)航等常見技能一鍵可用,需要加大模型就直接接 LLM、VLM、VLA,還自帶參考 Demo,稍改即可落地,大幅縮短從“裸機(jī)”到“能干活的機(jī)器人”的周期。
破冰前行,開放致遠(yuǎn)
與動(dòng)輒“全家桶、一鍋端”的封閉路線不同,英特爾的“大小腦融合”選擇的是一條更開放、更有彈性的技術(shù)路徑:
同一套代碼既能跑在 CPU/GPU/NPU/FPGA 上,也能在 Intel 與 Arm 平臺(tái)間自由切換;
主流 AI 框架與模型全兼容,不鎖庫、不鎖模型;
ROS2 與各類開源算法庫也全部敞開支持。
從底層算力、網(wǎng)絡(luò),到軟件棧、模型框架、應(yīng)用框架,企業(yè)都可以按需自由組合。這意味著,他們不必推翻既有系統(tǒng),也無需被某家供應(yīng)商鎖死,而是能夠在自己的 IT/OT 基礎(chǔ)之上、沿著現(xiàn)有行業(yè)生態(tài)繼續(xù)演進(jìn),把數(shù)據(jù)和大模型真正變成生產(chǎn)力。
過去幾個(gè)月里,英特爾已與國內(nèi)數(shù)十家具身智能廠商深入合作,已有十余家進(jìn)入驗(yàn)證或 POC 階段。在技術(shù)與市場(chǎng)都充滿不確定性的具身智能賽道里,這種開放自由的體系,正成為越來越多機(jī)器人企業(yè)愿意嘗試的路線。
更多細(xì)節(jié),可參考英特爾具身智能白皮書。
免責(zé)聲明:市場(chǎng)有風(fēng)險(xiǎn),選擇需謹(jǐn)慎!此文僅供參考,不作買賣依據(jù)。
標(biāo)簽:
- 人形機(jī)器人的落地難題,竟被一頓“九宮格”火鍋解開?
- 騰訊云9月金秋上云季:爆品秒殺,優(yōu)惠低至骨折價(jià),概澤科技限時(shí)回饋!
- 八達(dá)嶺長(zhǎng)城現(xiàn)“好漢磚”熱潮
- 共筑量產(chǎn)級(jí)L4物流新生態(tài) 奇瑞商用車與輕舟智航完成戰(zhàn)略合作簽約
- 面向創(chuàng)新創(chuàng)業(yè)人才!最高800萬!2025年度晉江市高層次創(chuàng)新創(chuàng)業(yè)人才(團(tuán)隊(duì))項(xiàng)目正在申報(bào)中
- IPIDEA靜態(tài)住宅代理實(shí)現(xiàn)多平臺(tái)電商數(shù)據(jù)無障礙采集
- AMD公布2025年第三季度財(cái)報(bào)
- 西平答卷:一個(gè)中原縣城的文明鄉(xiāng)風(fēng)與重陽華章
- 居家水光的風(fēng)險(xiǎn)有哪些?東方佰麗褪紅抗炎能力更適配東方肌膚
- 七麥×AppSa 2025全球應(yīng)用App增長(zhǎng)峰會(huì)深圳站圓滿舉辦!以實(shí)戰(zhàn)經(jīng)驗(yàn)賦能 App全球增長(zhǎng)!